

Agents and Lab Automation


With all the buzz around LLMs, many have been trying to use them to open the floodgates to automated research. Agentic AI scientists that can come up with hypotheses, design experiments, program lab robots, and analyse the results.
I’m sceptical – at least in the short term. Not sceptical that LLMs can add tremendous value to the scientific process. There are tonnes of use-cases and companies building products to streamline science. Take a look at the newest literature search tools; smarter hypothesis generation; the application of language models to protein engineering… the list goes on.
What I’m sceptical of are the visions of a scientist deciding on an experiment they’d like to run, and pressing go. A cloud of agents descending on the problem. Picking it apart, researching it, designing the perfect experiment, programming the robots, analysing the data, and presenting the results back to the scientist.
Why am I sceptical? Although there’s plenty of evidence that AI can do a great job at a number of these tasks (certainly for simpler experiments), the trouble comes in stringing these tasks together.
Our own experience building an AI-driven product largely aligns with this excellent blog post by Utkarsh Kanwat. The crux of it comes down to compounding error. Even with error rates at 95%, agentic workflows with only 10 steps fail 41% of the time.
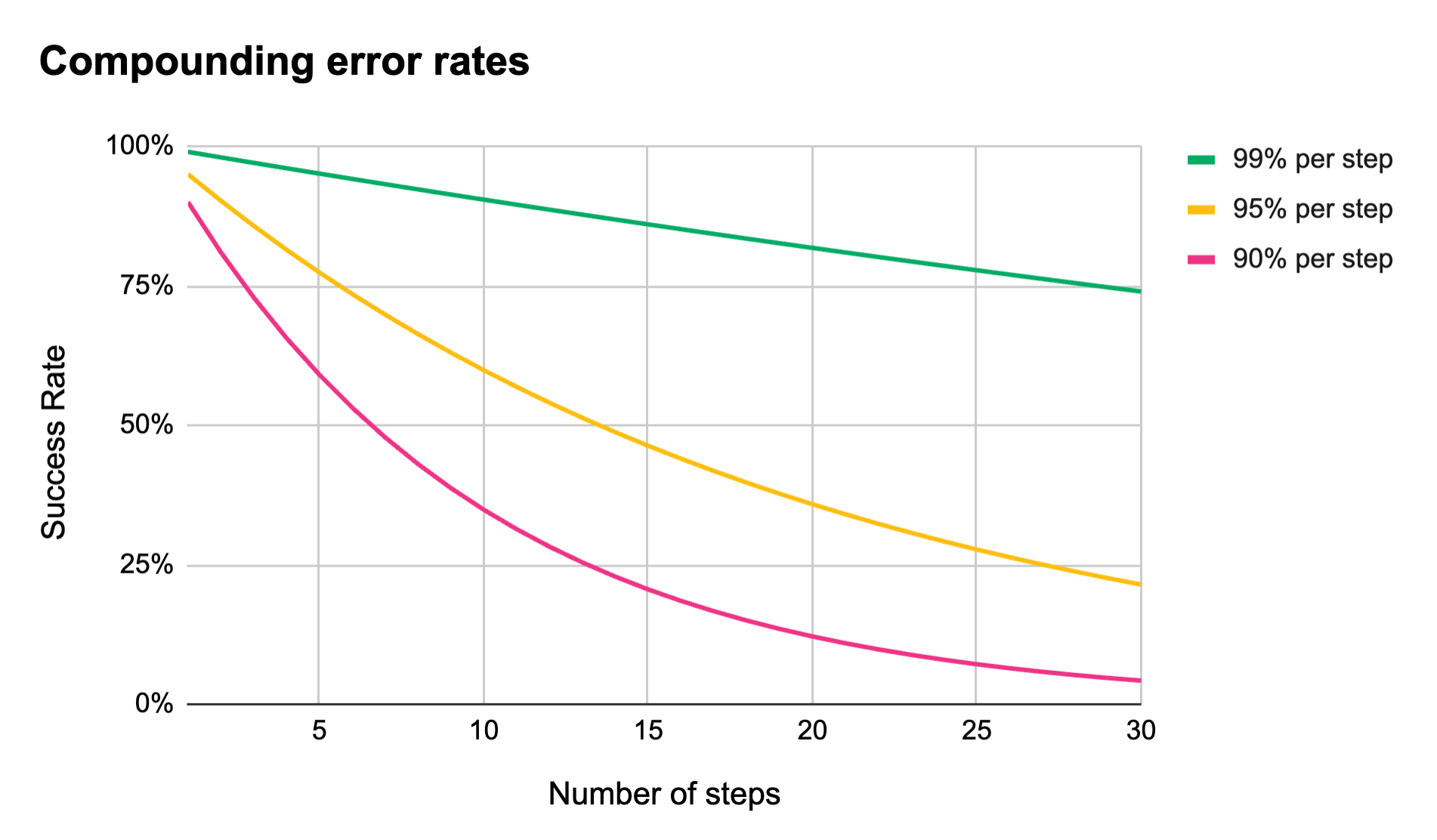
As long as AI continues to be prone to hallucination, these kinds of complex agentic workflows will have unacceptable failure rates. This is true even in domains where there are vast quantities of well written documentation for LLMs to learn from. It is even worse in the business of automating science, where the tiniest details matter, and these details may never have been published outside of a single scientist’s notebook.
And then there’s lab automation. Much development and maintenance is handled by the vendors themselves, with detailed, publicly available documentation taking a backseat in favour of a service call. And while there’s some growth in automation developer forums and peer-to-peer help, there are orders of magnitude less for LLMs to learn from than in software developer communities.
All of this taken together, means that successfully building useful, reliable products with AI requires us to build systems and interfaces around LLMs, to ensure errors are caught before a precious experiment is wasted. We cannot surrender to the swarm of agents just yet.
A Case Study in Lab Automation
Let’s look at this problem through the specific lens of automation so I can explain a little more in depth:
A fully integrated, agentic workflow for lab automation would likely look something like this:
A scientist describes the experimental question they would like to answer to the LLM through a prompt.
The intent is broken down into a concrete protocol, with all the implicit steps and parameters made explicit.
Laboratory workcells and equipment are selected that fit the protocol that has been designed.
The protocol is translated into appropriate code for the laboratory automation.
Instructions are generated for the operator to setup and run this particular experiment in the lab.
Automation code is sent to the robots, and instructions are sent to the operator to get started.
Tangled protocols
Imagine an error is introduced while the LLM is creating the protocol – perhaps the wrong amount of enzyme is added, or a control is forgotten (yes, AIs do this too!) – this error will propagate through to the robot, and the experiment is doomed.
The AI does not even need to ‘hallucinate’ to go astray. it may just lack the requisite context that it needs from the scientist to design the appropriate protocol.
To solve this, the scientist needs an opportunity to check the AI’s work. They need to ensure that the protocol matches their expectations. That means we need an interface here – a clear, unambiguous description of how the AI intends to test the hypothesis, with an easy way for the scientist to make changes if it has gone awry.
Translating to automation code
Errors or hallucinations introduced into the automation code are just as problematic. This might result in anything from a cryptic error message, to a full-on crash.
A solution here is a little more tricky. Let’s say we add another interface for the scientist to check. We could show the scientist the code before it is sent to the robot? Well this falls at the first hurdle. Most scientists don’t code, so spotting errors here is going to be a non-starter.
Our next option is a user interface. We could show the AI generated workflow in the vendor’s interface and have the scientist check it through there?
Well, this doesn’t really work either – for a couple of reasons.
The first is that most of these user interfaces are… challenging for a newcomer to use or interpret. Many require multiple day training courses to get to grips with, and a months or years of experience to become truly proficient. They were never designed for a scientist.
Secondly, in order to spot potential errors in automation code, being able to understand the workflow is only half the battle. the user also need a deep understanding of how the machine works – it’s constraints, it’s deck, it’s little quirks. In short, you need to understand the software and the hardware… In even shorter, you need to be an automation engineer.
This means that looping in the scientist with existing tooling alone won’t solve the problem here. We need a two-pronged approach.
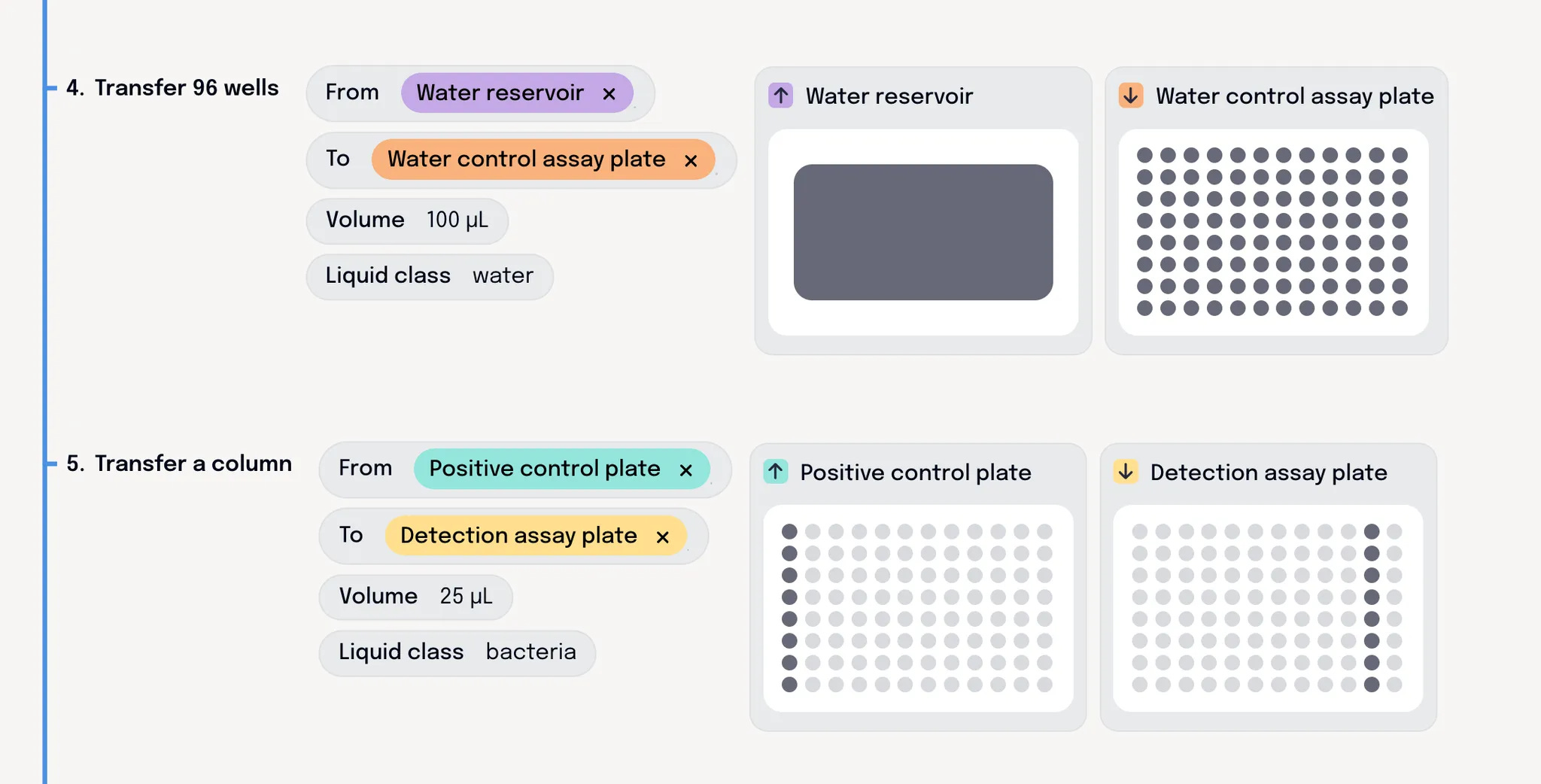
First we need a clear view of precisely what the robot is going to do, expressed in terms that scientists can actually understand. We think this means introducing more abstraction. Clear actions that they recognise from their day job. Stuff like tip-tracking and deck definitions needs to be taken care of behind the scenes.
Here’s a look at Briefly’s protocol view to give you an idea of how we think these workflows should be visualised.
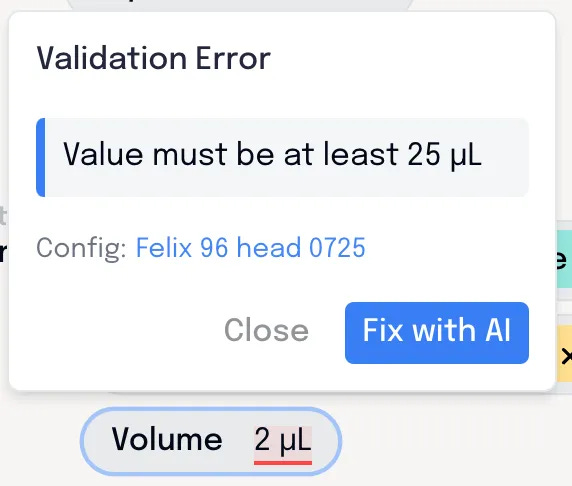
Critically, they need more layers of validation and simulation: Old fashioned, deterministic software that ensures the workflow can actually be run on the robot, and won’t cause any errors or crashes. Any issues need to be clearly conveyed to the scientist so they can understand the issue, and make adjustments to get around it. Whether that’s switching to a different piece of labware, or adjusting their pipetting volumes.
Heres’s our validation engine at work, pointing out issues to the user to be tweaked before it heads to the robot.
There is no shortcut
In fields like ours, there are few easy wins with AI. Getting value from LLMs means taking a step back, and thinking about the workflow and its users – how can we unlock automation for a whole new group of scientists, while mitigating the inherent risks and shortcomings of these models?
We’re tackling these problems from the ground up. If you’re interested in integrating Briefly’s software with your lab robots, let’s have a chat!
Love this!