

How to make lab automation flex as science evolves
Briefly’s new interface with lab automation


Tl;dr: We’re developing a new interface for lab automation that lowers the barrier to programming robots, and brings more flexibility to automating science. We’ll be demoing this at SLAS at our booth and with our partners at Biosero.

Last year, we attended SLAS. It was our first conference, and we were showing off the very first version of our product. Principally, it was a protocol builder. It used LLMs to take free text descriptions of methods, and convert these into a consistent structure, with steps and parameters explicitly documented.
We built this to help with reproducibility. To help produce consistent documentation that can be handed off from one scientist to the next more easily. At SLAS, we were somewhat inundated, not by scientists, or managers, but by automation engineers.
Although this protocol structure was not designed explicitly for automated systems, they saw potential in it that we missed. By starting to standardise how protocols are documented, we had taken one step towards tackling a key problem in lab automation: translating a scientist’s intent into a concrete automated process.
However, there was a core part of the puzzle missing. Without standardising the language of these protocols, and applying the constraints of automated systems, a protocol in Briefly could never be understood by automation.
This year at SLAS, we’re announcing our the next step on that path: automatic protocol validation, and adaptation for lab automation.
Before we go into that, a little context.
The complexity of lab automation software
Different automated systems have different ways of defining their protocols. They use different formats, different language, and have different constraints based on the specific constellation and configuration of equipment in that lab.
These wide ranging requirements end up in vendor software, which makes their interfaces unnecessarily complex for many applications. For example if you are running two plates per day, a scheduler that interleaves plates isn’t necessary. But interleaving plates is core to how many automation user interfaces are built.
This makes defining automated protocols really difficult without deep knowledge and understanding of your automated system. In practice this is the job of the automation engineer – working inside the lab itself, or at the automation vendor.
What’s the problem?
To build this automated system, huge time and energy is spent with scientists to understand and map the scientific workflow, adapt it to work with automated systems, then develop, and test these workflows. Depending on the complexity of the protocol, this can take weeks, months, even years.
This doesn’t have to be the end of the world – if that workflow is static. It can be run and run and investing that time ends up worth it.
But so much science isn’t static – it evolves and flexes as requirements change, projects move on, and methods are optimised. The scientists responsible for these changes don’t have the skills, or frankly the time, to make these adjustments.
This means that automation engineers need to be involved in even the smallest of changes. The time and effort spent programming and validating these changes means scientists often just move back to running things by hand and all the benefits of automation are lost.
A different model for lab automation
We think that a better model for lab automation exists – one that accommodates more of science’s fluidity. This model is built on more modularity and abstraction. Let’s walk through a simple automation task to illustrate.
Imagine you have a small work-cell, comprised of a liquid handler, an incubator and an arm. You have been asked to automate the growing and feeding of a particular organism. The protocol looks something like:
Grow for 24h
Add 50uL growth media
Grow for 24h
Add 50uL growth media
As the engineer, broadly you have two options. You can build and validate a system that runs the exact protocol above. Or you could build two reusable blocks: “Dispense media” and “Incubate”.
Developing the whole thing means you only have to validate it for this specific case. User interaction is simple – the scientist presses ‘go’ and it runs exactly as it was programmed. But if the scientist tweaks their protocol, they are powerless to change the automation without your help and without more validation, and they go back to running it manually.
Modularity brings flexibility
Taking the modular approach is harder up-front. You’ll need to design your building blocks and decide what level of control to expose to the user. For the dispense step, giving the users the flexibility to dispense a range of volumes, say, 1-100uL, means testing and validating the liquid handling across that range, and defining allowed labware that can handle it.
Having done the same work for the incubate step, you’ll need to validate these blocks together in various constellations and with varying parameter ranges in the lab. Only then can we can build the specific workflow that was requested.
This is more work, for sure, but this system has flexibility built-in. It allows for tweaks, adaptations and optimisations. The user can focus on variables that are relevant to the science without having to re-think and re-validate the rest of the automation each time.
This isn’t a new idea – these abstractions are being built. But much of the time, they are built for the engineer, to make their life easier as they develop and as the protocol evolves.
However, with a better interface for the scientist, we think there’s potential for these abstractions to empower scientists more directly.
A better interface with the scientist
As I mentioned earlier, automation software is not built for scientists. It does not allow them to work in a way that is familiar to them, or to focus on the steps and parameters of their protocol.
To empower scientists, we need something simpler. It must:
display the protocol in a way that makes intuitive sense to them,
actively help them to adapt their protocols to the language and constraints of the automated system,
accommodate the different constraints from different automation set-ups.
How this works in Briefly
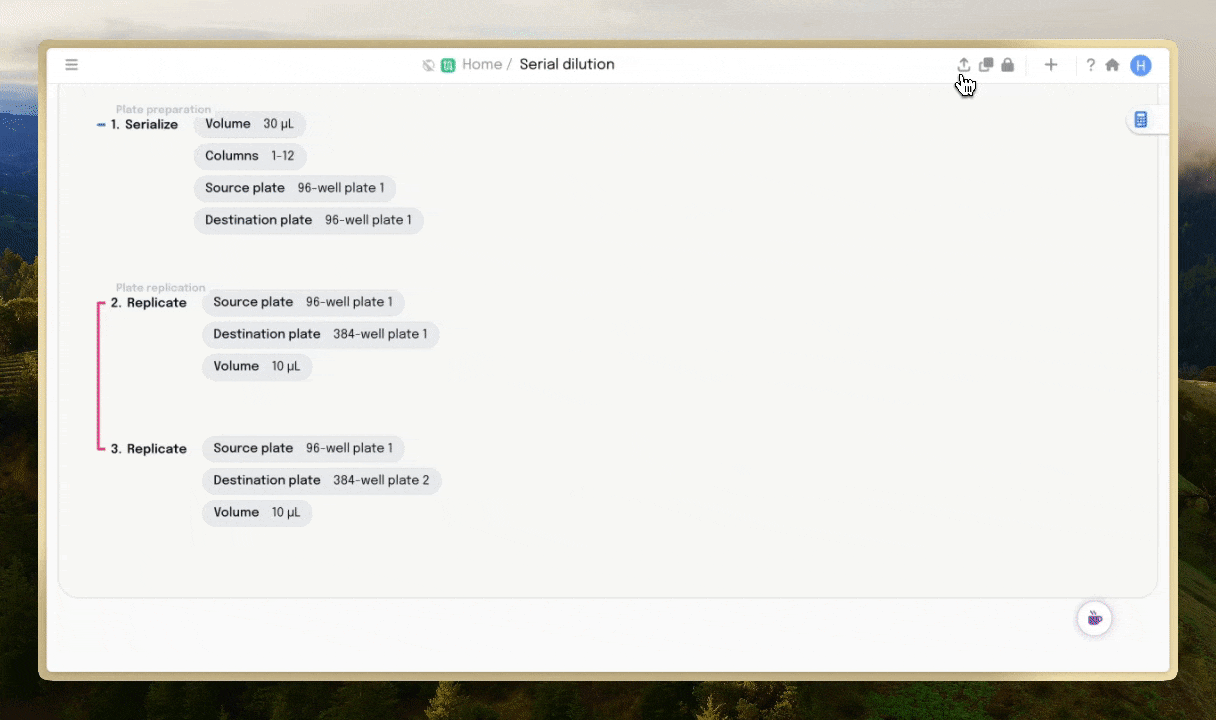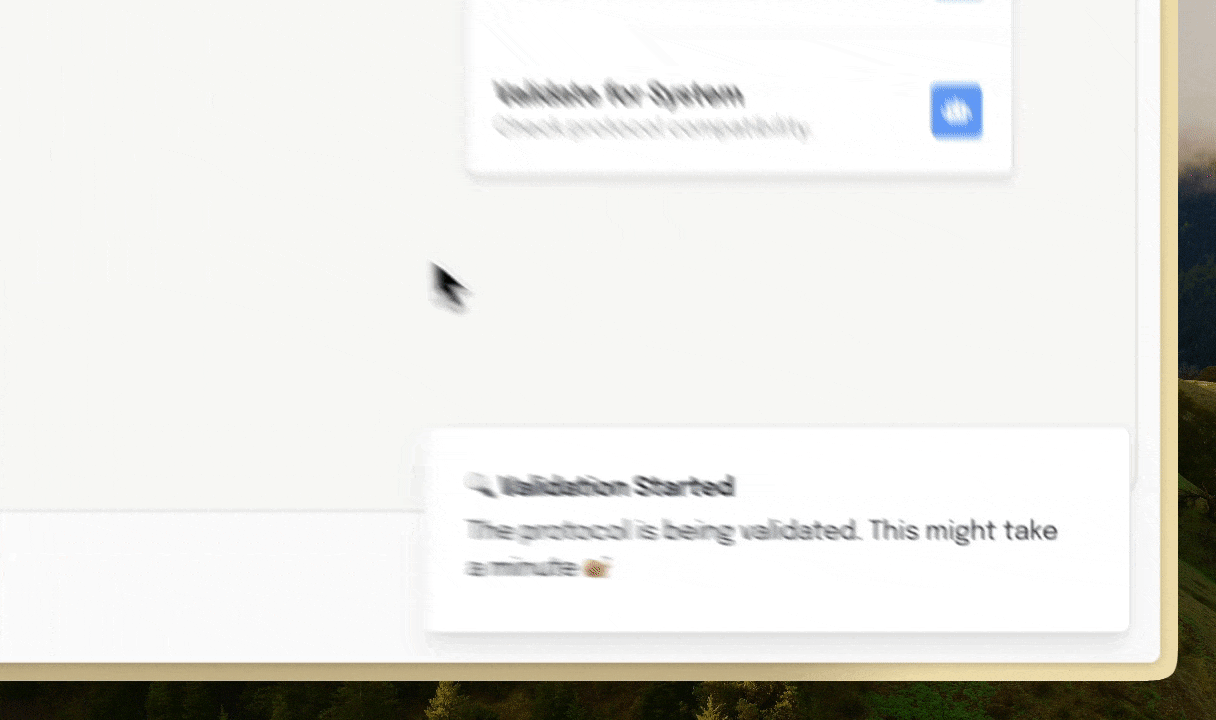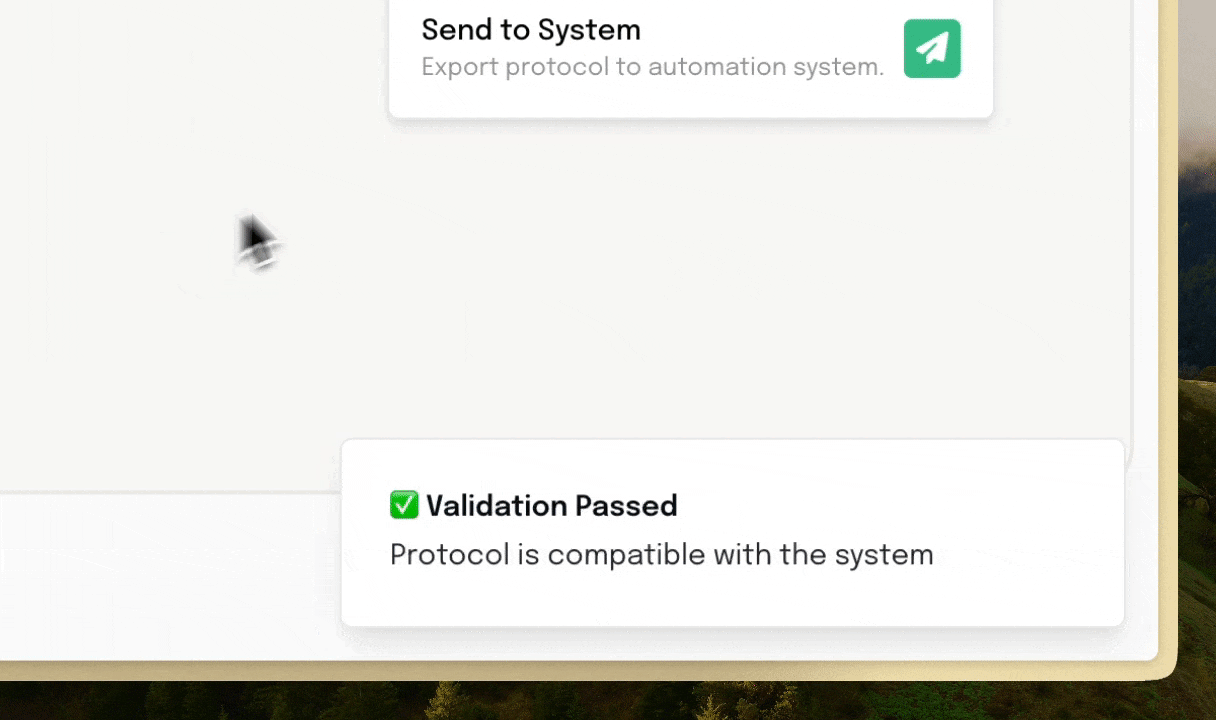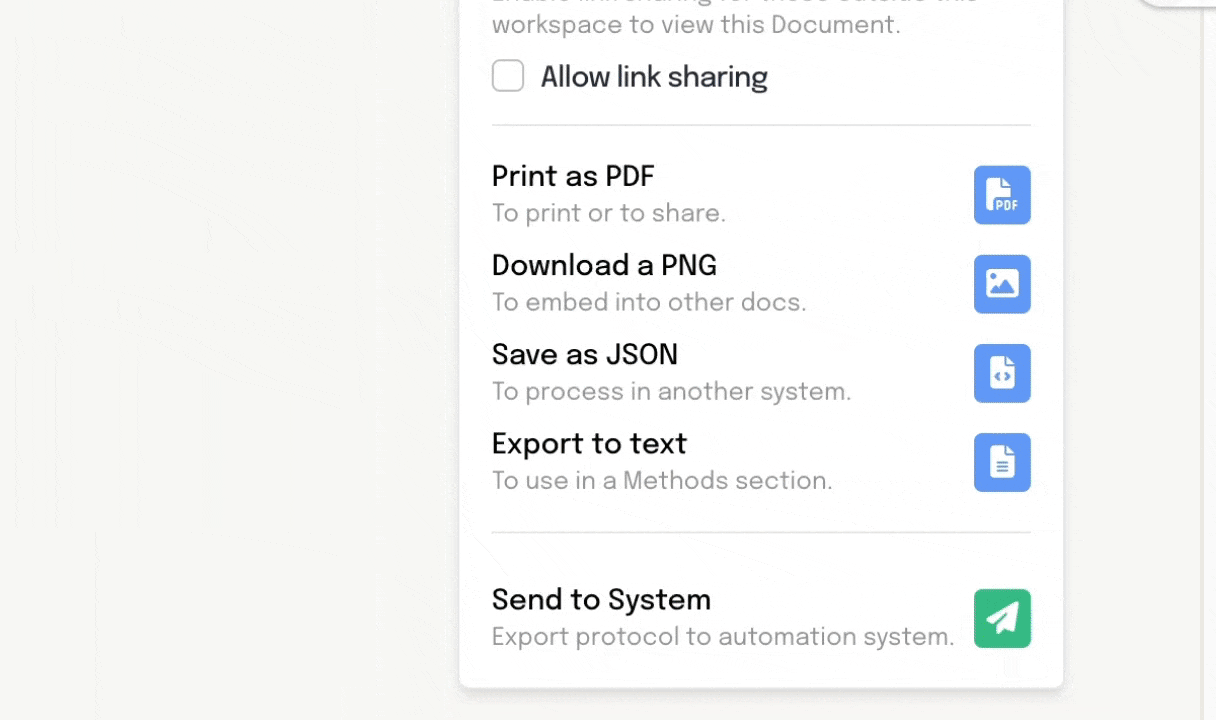
Let’s go through an example of how to get a protocol ready for automation in Briefly, from start-to-finish. First, scientists can use Briefly to convert unstructured text-based protocols and into our structured, step-by-step format.

The constraints of any automated system can then be imposed onto these protocols. Once a protocol is imported to Briefly, it can be checked against these constraints. For example, if there’s a centrifuge step in the protocol but no centrifuge, Briefly will flag this to the user. If critical parameters aren’t defined, the user will be nudged to complete them.

This is a nice start, but it still leaves the user to fix all of these issues. To alleviate this, we allow AI to perform a first-pass at making the tweaks. Understanding the constraints, it can fill in the parameters where they’re missing, remove or re-word steps that don’t align with the constraints of the system.

Importantly, this is all transparent to the scientist. Each and every step in a protocol can have an impact on the resulting data. The scientist needs to understand exactly what is going to happen and retain agency and control over the design process.
This transparency is so often lacking in how automated protocols are developed today, since they are programmed by the automation engineer, in software that the scientist doesn’t understand.
Once the checks pass, the protocol can be sent to the scheduling software that runs a work-cell, or even used to run an individual device.
Come see our demo at SLAS
We’re demoing this at SLAS. Come see us at booth #1252, or at our partners Biosero at Booth #1330 and take a look for yourself. If you can’t make it, reach out! We’re looking for more automation vendors and teams to partner with on this, as well as end users to build alongside. Let’s chat!